
如何设计一个高并发系统
有过高并发实践经验的当然最好了,但事实是这很难,除非是这家公司是匹黑马,你刚去的时候用户不多,但是行业发展好,每月几百万用户用户的增长,你不断的踩坑,不断地升级公司的系统架构,现在不太可能实现了,互联网巨头们都已经尘埃落定,所以大部分人基本上也碰不到这些个情况了,但是互联网公司面试要问呐,咋整?
第一类当然是最好的,有过经验的,没有怎么办?退而求其次!你没吃过猪肉还没见过猪跑?把理论玩精了,总比对高并发系统一无所知的人要好的多吧。
如果你属于第二种情况,试试从下面六个方面来设计一个高并发的系统:
- 系统拆分
- 缓存
- MQ
- 分库分表
- 读写分离
- ElasticSearch
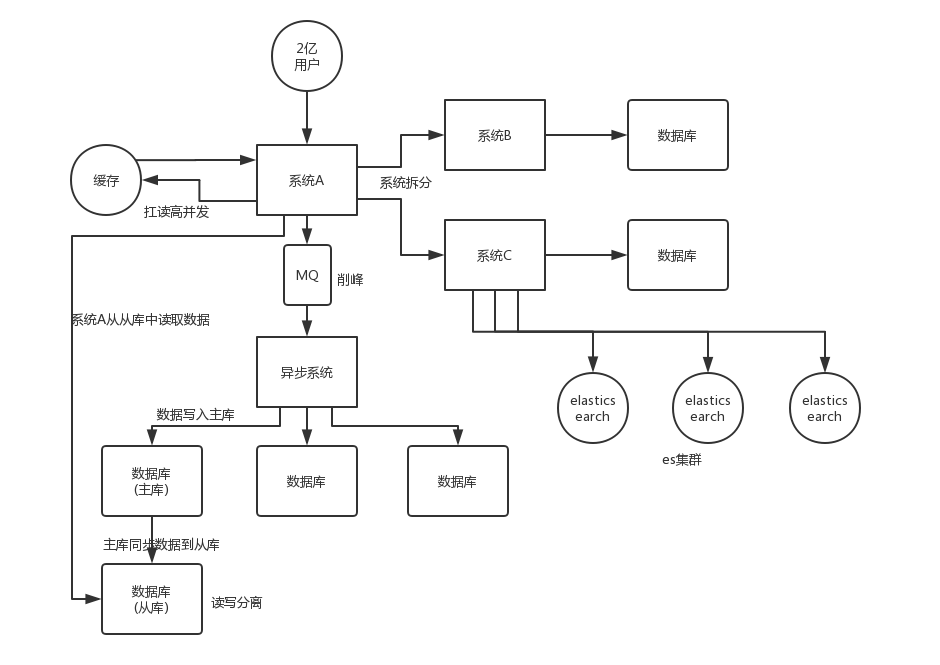
系统拆分
将一个系统拆分为多个子系统,用 dubbo 来搞。然后每个系统连一个数据库,这样本来就一个库,现在多个数据库,不也可以扛高并发么。
缓存
缓存,必须得用缓存。大部分的高并发场景,都是读多写少,那你完全可以在数据库和缓存里都写一份,然后读的时候大量走缓存不就得了。毕竟人家 redis 轻轻松松单机几万的并发。所以你可以考虑考虑你的项目里,那些承载主要请求的读场景,怎么用缓存来抗高并发。
MQ
MQ,必须得用 MQ。可能你还是会出现高并发写的场景,比如说一个业务操作里要频繁搞数据库几十次,增删改增删改,疯了。那高并发绝对搞挂你的系统,你要是用 redis 来承载写那肯定不行,人家是缓存,数据随时就被 LRU 了,数据格式还无比简单,没有事务支持。所以该用 mysql 还得用 mysql 啊。那你咋办?用 MQ 吧,大量的写请求灌入 MQ 里,排队慢慢玩儿,后边系统消费后慢慢写,控制在 mysql 承载范围之内。所以你得考虑考虑你的项目里,那些承载复杂写业务逻辑的场景里,如何用 MQ 来异步写,提升并发性。MQ 单机抗几万并发也是 ok 的,这个之前还特意说过。
分库分表
分库分表,可能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就将一个数据库拆分为多个库,多个库来扛更高的并发;然后将一个表拆分为多个表,每个表的数据量保持少一点,提高 sql 跑的性能。
读写分离
读写分离,这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都集中在一个库上吧,可以搞个主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库。
ElasticSearch
Elasticsearch,简称 es。es 是分布式的,可以随便扩容,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来扛更高的并发。那么一些比较简单的查询、统计类的操作,可以考虑用 es 来承载,还有一些全文搜索类的操作,也可以考虑用 es 来承载。
其实大部分公司,真正看重的,不是说你掌握高并发相关的一些基本的架构知识,架构中的一些技术,RocketMQ、Kafka、Redis、Elasticsearch,高并发这一块,你了解了,也只能是次一等的人才。对一个有几十万行代码的复杂的分布式系统,一步一步架构、设计以及实践过高并发架构的人,这个经验是难能可贵的。